命令行使用笔记
杀掉所有占用GPU的进程,在宿主机使用可以杀掉容器里面的进程:sudo fuser -v /dev/nvidia* |awk '{for(i=1;i<=NF;i++)print "kill -9 " $i;}' | sudo sh
杀掉所有的进程2:ps -ef|grep python\ push_data.py| awk '{print $2}'| xargs kill
批量删除进程:ps -ef | grep firefox | grep -v grep | awk '{print "kill -9 "$2}' | sh
使用tensorboard命令:tensorboard --logdir=runs --port=60010 --bind_all
convert albert cammand: python3 convert_albert_tf_checkpoint_to_pytorch.py --tf_checkpoint_path=/Users/apple/Downloads/albert_xlarge_zh_183k/ --bert_config_file=/Users/apple/Downloads/albert_xlarge_zh_183k/albert_config_xlarge.json --pytorch_dump_path=/Users/apple/Desktop/albert_xl.bin
获取当前文件夹大小的命令:du -h -d 1
统计文件行数:wc -l filename

四列内容分别是:行数、字数、字节数、文件名
文件合并:cat file1 file2 > file3
删除当前目录下小于50000KB的文件:for file in `ls ./`; do size=`du $file | awk '{print \$1}'`; [ $size -lt 50000 ] && rm $file; done
查看gpu上有哪些程序在跑的命令:sudo fuser -v /dev/nvidia*
在transformers的src/transformers/的目录下转换albert的tf模型到pytorch模型:python3 convert_albert_original_tf_checkpoint_to_pytorch.py --tf_checkpoint_path /Users/apple/Desktop/albert_xxlarge/model.ckpt-best.index --albert_config_file /Users/apple/Desktop/albert_xxlarge/albert_config.json --pytorch_dump_path /Users/apple/Desktop/pytorch_model.bin
curl模拟post传输json:curl -d '{"text":"北京市第一中学"}' http://192.168.2.7:5557/expand2
python环境导出和安装:
pip freeze > requirements.txt
pip install -r requirements.txt
查看磁盘用量以及文件夹挂载:df -lh
查看详细挂载信息:mount
查看磁盘详细信息:fdisk -l
查看磁盘读写状态,%util表明磁盘的io被占满了:iostat -x 1
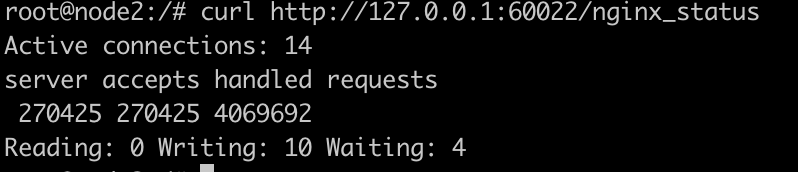
检测nginx状态:
server {
listen 60022;
server_name 127.0.0.1;
location /nginx_status {
stub_status on;
access_log off;
allow 127.0.0.1;
# deny all;
}
}#在自己的server中加入第4行到第9行的代码
#然后nginx -s reload
#再curl http://127.0.0.1/nginx_status
结果展示:
使用curl获取es的mapping,通过账号密码: curl --user elastic:WbuchSIF0qsqaGBvTsGV -XGET 'http://192.168.3.171:9210/similar_en_v1/_mapping'
使用redis-cli带用户名和密码进行登录:./src/redis-cli -h 127.0.0.1 -p 6379 -a lt2020
#-a后面跟的是密码
redis-cli -h 192.168.2.55 -p 19000 -a laibo -c
# -c表示连接集群
使用命令行跑java程序: java -Xms16g -Xmx16g -classpath classes:lib/* com.yiciyuan.similar.index.Main id
crontab如果需要环境变量,例如java命令,则需要在shell脚本里加以下的命令:
#!/bin/sh
source /etc/profile如果crontab不执行命令,可能是时区不同,可以用date命令看一下时间。
查看crontab执行记录:tail -f /var/log/cron
进入docker容器 :docker exec -ti <your-container-name> /bin/sh
进入pod:kubectl exec -ti <your-pod-name> -n <your-namespace> – /bin/sh
在同一分钟内多少个相同操作的sql语句:select date_format(f_post_time,'%Y-%m-%d %H:%i'),count(*) from t_Task group by date_format(f_post_time,'%Y-%m-%d %H:%i')
让cpu满载的命令:for i in `seq 1 $(cat /proc/cpuinfo |grep "processor" |wc -l)`; do dd if=/dev/zero of=/dev/null; done
命令行连接mysql:mysql -P 3306 -h 192.168.1.104 -u root -p
查询一个进程有多少个线程:ps hH p pid | wc -l
查看网卡情况ethtool em1 #em1是网卡的名称,可以通过ifconfig查看
查看网速:dstat -cmdnl
python启动简易服务器:python -m SimpleHTTPServer
docker run -d --name milvus_cpu_0.9.0 -p 19530:19530 -p 19121:19121 -p 9091:9091 -v /home/lt/milvus/db:/var/lib/milvus/db -v /home/lt/milvus/conf:/var/lib/milvus/conf -v /home/lt/milvus/logs:/var/lib/milvus/logs -v /home/lt/milvus/wal:/var/lib/milvus/wal milvusdb/milvus:0.9.0-cpu-d051520-cb92b1
删除timemachine里面的备份文件命令:for line in $(tmutil listlocalsnapshots / | awk -F '.' /'TimeMachine./ {print $4}');do tmutil deletelocalsnapshots $line ;done
查看文件夹大小(mac可以用):du -sh *
挂载网络盘:mount -t cifs //192.168.6.120/D$ /disk1 -o username=administrator,password='6jgVX*Pc',rw,uid=0,gid=0
mvn编译到k8s的命令mvn -DharborUser=admin -DharborPassword=Laibokeji -Dbranch=lt -DbuildTime=202006181016 compile jib:build
centos的vim显示中文乱码,centos本身没有中文乱码:#修改/etc/vimrc,在文件顶部加上下面四行即可
set fileencodings=ucs-bom,utf-8,gbk,gb2312,cp936,gb18030,big5,latin-1
set encoding=utf-8
set termencoding=utf-8
set fileencoding=utf-8追加文件:# 使用>>将文本流将文件添加到另外一个文件的末尾
cat file1.txt >> file2.txt打乱一个文件的所有行:
#将a.txt里面的行打乱输出到b.txt
shuf a.txt -o b.txt
split命令
split -l 300 need_split.txt -d -a 2 splited
# -l表示按行分割
# -d表示后缀增加使用数字,-a表示使用多少个数字
# splited是生成的文本的前缀
rename命令
批量修改目录下所有文件的后缀名,txt修改为csv
rename 's/.csv/.txt/' *
批量把目录下所有文件名中大写改为小写
rename 'y/A-Z/a-z/' *
删除当前目录下所有文件的后缀名
rename 's/.csv//' *
或者
rename 's/.bak$//' *.bak
给所有文件添加后缀名
rename 's/$/.txt/' *
统一在文件名前添加某个字符串
rename 's/^/goodluck/' *
找到pv挂载在哪个位置:
kubectl get pv pvc-1557d839-714f-11e9-8d1a-5065f3457c8c
使用rdb命令卸载挂载的盘
rbd unmap /dev/rbd8
findAndRemove,findAndModify 是原子操作,这样可以保证一条只被一个进程拿到。
printenv可以打印环境变量
#python获取环境变量
import os
env = os.environ()
print(env.get('JAVA_HOME'))
# 打印所有环境变量,遍历字典
for key in env:
print key + ' : ' + env[key]
mac格式化U盘
brew install e2fsprogs
diskutil list
diskutil unmountdisk /dev/disk2s1
sudo $(brew --prefix e2fsprogs)/sbin/mkfs.ext3 /dev/disk2s1
pytorch 多GPU训练:
CUDA_VISIBLE_DEVICES=6,7 OMP_NUM_THREADS=1 nohup python -u -m torch.distributed.launch --master_port 6666 --nproc_per_node=2 run_seq2seq.py --data_dir ./data/ --src_file output_3_10w.jsonl --model_type unilm --model_recover_path ./original_model/pytorch_model.bin --model_name_or_path ./original_model --output_dir ./model_output --max_seq_length 512 --max_position_embeddings 512 --do_train --fp16 --do_lower_case --train_batch_size 20 --learning_rate 1e-5 --num_train_epochs 5 > klogger.log 2>&1 &
echo "命令执行完,进入log查看"
tail -f klogger.log
计算当前文件夹有多少个文件
ls -l | grep "^-" | wc -l
hbase相关知识
术语
Table(表):HBase table 由多个 row 组成。
Row(行):每一 row 代表着一个数据对象,每一 row 都是以一个 row key(行键)和一个或者多个 column 组成。row key 是每个数据对象的唯一标识的,按字母顺序排序,即 row 也是按照这个顺序来进行存储的。所以,row key 的设计相当重要,一个重要的原则是,相关的 row 要存储在接近的位置。比如网站的域名,row key 就是域名,在设计时要将域名反转(例如,org.apache.www、org.apache.mail、org.apache.jira),这样的话, Apache 相关的域名在 table 中存储的位置就会非常接近的。
Column(列):column 由 column family 和 column qualifier 组成,由冒号(:)进行进行间隔。比如family:qualifier。
Column Family(列族):在 HBase,column family 是 一些 column 的集合。一个 column family 所有 column 成员是有着相同的前缀。
比如, courses:history 和 courses:math 都是 courses 的成员。冒号(:)是 column family 的分隔符,用来区分前缀和列名。column 前缀必须是可打印的字符,剩下的部分列名可以是任意字节数组。column family 必须在 table 建立的时候声明。column 随时可以新建。在物理上,一个的 column family 成员在文件系统上都是存储在一起。因为存储优化都是针对 column family 级别的,这就意味着,一个 column family 的所有成员的是用相同的方式访问的。
Column Qualifier(列限定符):column family 中的数据通过 column qualifier 来进行映射。column qualifier 也没有特定的数据类型,以二进制字节来存储。比如某个 column family “content”,其 column qualifier 可以设置为 “content:html” 和 “content:pdf”。虽然 column family 是在 table 创建时就固定了,但 column qualifier 是可变的,可能在不同的 row 之间有很大不同。
Cell(单元格):cell 是 row、column family 和 column qualifier 的组合,包含了一个值和一个 timestamp,用于标识值的版本。
Timestamp(时间戳):每个值都会有一个 timestamp,作为该值特定版本的标识符。默认情况下,timestamp 代表了当数据被写入 RegionServer 的时间,但你也可以在把数据放到 cell 时指定不同的 timestamp。
ubuntu计算md5的命令是:md5sum
mac上计算md5是:md5
linux查看本机和那些ip建立了链接的命令,以及找到对应进程的启动文件:
netstat -antlp
lsof -p:pid
使用kubectl创建pod
kubectl apply -n marktool -f marktool.yaml
在代码里指定某些显卡可见:
import os
os.environ['CUDA_VISIBLE_DEVICES']="4,5,6,7"
查看mongo的连接数:
db.serverStatus().connections
redis 复制set:将key1复制给key2,temp是空的,不用管。
SUNIONSTORE key2 key1 temp
查看机器的kill log:
dmesg | egrep -i -B100 'killed process'
提取文件的中间几行:
sed -n '400,500p' name.txt > new.txt
安装python3.8 和 pip3
apt update
apt install -y python3.8 python3.8-dev
cd /etc/bin
ln python3.8 python
ln python3.8 python3
apt install -y python3-pip
ln pip3 pip
扫描内网IP:
#!/bin/bash
for ip in $(seq 1 254);do
ping -c 1 192.168.50.$ip | grep '64 bytes' | cut -d " " -f 4 | tr -d ":" &
done
ssh 重启,docker中也可以用
/etc/init.d/ssh restart
查看文件夹下面文件数量:(rclone版本)
rclone ls ningxias3://esdata.laibokeji/redis/ | grep "appendonly.aof"| wc -l
对比文件夹下面文件:
for file in `rclone ls ningxias3://esdata.laibokeji/redis/ | awk '{print $NF}'`; do find 1 -type f -iname "$file" | awk '{print $NF}' ; done | wc -l
iftop可以实时监控流量状态
命令行设置代理:
export ALL_PROXY=socks5://127.0.0.1:20170
export http_proxy=http://127.0.0.1:20171
export https_proxy=http://127.0.0.1:20171
git tag
git tag #列出所有tag
git tag -l * #利用通配符过滤tag
git tag v1.0 #新建一个tag
git tag -a tagname -m "comment" #创建带注释的tag
git show tagname #查看tag的详细信息
git tag -a v1.0 commitid -m "comment" #给指定的commit添加tag
git push origin tagname #将指定tag推送到远程
git checkout tagname #切换到某个tag,不在任何branch
git tag -d tagname #删除某个tag
git push origin :refs/tags/v1.0 #删除某个tag
导出项目里面使用的python环境:
pipreqs . --encoding=utf8 --force
清除没用的docker 镜像
docker image prune
清楚python环境:
apt-get purge -y python.*
pip 运行的时候遇到的问题:
subprocess.CalledProcessError: Command '('lsb_release', '-a')' returned non-zero exit status 1.
https://stackoverflow.com/questions/44967202/pip-is-showing-error-lsb-release-a-returned-non-zero-exit-status-1
vim /usr/bin/lsb_release
在最上面一行,指出自己使用的python的详细版本,例如 #!/usr/bin/python3.8.6 -Es
按照文件大小进行查找
sudo find / -size +500M
sudo find / -size +10G
挂载新的硬盘
lsblk # 查看磁盘的名字
blkid # 查看uuid
fdisk -l # 查看磁盘硬件信息
mkfs.ext4 /dev/sdg # 格式化硬盘
mount /dev/sdg /data/sdg # 挂载硬盘
vim /etc/fstab # 打开fstab,用于开机自动挂载,加入以下的命令
UUID=63295b70-daec-4253-b659-821f51200be9 /home/data ext4 defaults,errors=remount-ro 0 1 # 加入磁盘自身的uuid
ansible判断文件文件数量,并且写入文件
ansible all -f2000 -mshell -a "ls /mnt/ok/ok/ |grep plot$ | wc -l" > filecount.txt
软链接的使用:
ln -s 源文件 目标文件
在命令行中临时加入代理
sudo apt-get -o Acquire::http::proxy="http://127.0.0.1:8000/" update
关于内核更新的命令:
uname -r # 查看内核版本,还可以-a
sudo apt update # 升级软件包,会自动更新内核信息
apt-cache search linux-image # 查看有哪些内核
sudo apt-get install linux-modules-nvidia-418-5.0.0-1043-oem-osp1 # 安装内核
sudo vim /etc/default/grub # 修改启动内核的版本
将GRUB_DEFAULT=0修改为你所想要还原的版本号,GRUB_DEFAULT="Ubuntu, with Linux linux-image-5.4.0-73-generic"
sudo update-grub # 更新grub,会显示有哪些内核
------------------------------------------
laibo@laibo-SYS-4029GP-TRT:~$ sudo update-grub
Sourcing file `/etc/default/grub'
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-5.4.0-74-generic
Found initrd image: /boot/initrd.img-5.4.0-74-generic
Found linux image: /boot/vmlinuz-5.4.0-73-generic
Found initrd image: /boot/initrd.img-5.4.0-73-generic
Found memtest86+ image: /boot/memtest86+.elf
Found memtest86+ image: /boot/memtest86+.bin
done
------------------------------------------
# 然后rm -rf /boot/vmlinuz-5.4.0-74-generic,rm -rf /boot/initrd.img-5.4.0-74-generic
# 这样就只有一个默认内核了,不删掉的话会有多个内核,会进入grub的选择界面,需要图形,机器不在身边的话很麻烦
dpkg --get-selections| grep linux # 查看已安装的内核
dpkg --list | grep linux-image # 查看使用过哪些内核
# 查看内核安装情况,会有多个内核的情况
dpkg --list | grep linux-image
dpkg --list | grep linux-headers
# 卸载内核
sudo apt purge linux-image-xx
sudo apt purge linux-headers-xx
sudo apt autoremove
# 关闭内核自动更新
sudo apt-mark hold linux-image-generic linux-headers-generic
# 开启
sudo apt-mark unhold linux-image-generic linux-headers-generic
查看Python的安装位置
python3.8-config --includes --libs
docker镜像加速方法:
# 我的阿里云docker镜像加速
https://c7l1jnym.mirror.aliyuncs.com
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://c7l1jnym.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
/etc/default/grub 文件说明
# If you change this file, run 'update-grub' afterwards to update
# /boot/grub/grub.cfg.
# For full documentation of the options in this file, see:
# info -f grub -n 'Simple configuration'
GRUB_DEFAULT=0
#属性名:默认启动项(就是我要的开机默认启动系统)
#值说明:
#数字:从0开始(按照开机选择界面的顺序对应)两级目录直接使用“1>3”,
#字符串:直接写选项的全名。二级目录下直接使用 > 大于号连接例如:“Advanced options for Ubuntu> Ubuntu, with Linux 4.9.90xenomai-3.0.7”
#saved:默认上次的启动项
#GRUB_HIDDEN_TIMEOUT=0
#属性名:是否隐藏菜单(grub2不再使用)
#值说明:0:不隐藏,1:隐藏
GRUB_HIDDEN_TIMEOUT_QUIET=true
#属性名:是否显示等待倒计时
#值说明:true:不显示,false:显示
GRUB_TIMEOUT=10
#属性名:进入默认启动项的等候时间
#值说明:单位:秒,默认10秒,-1表示一直等待
GRUB_DISTRIBUTOR=`lsb_release -i -s 2> /dev/null || echo Debian`
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash"
#属性名:内核启动参数的默认值
#值说明:quiet splash为不显示启动信息,安静的启动,如值为空则显示启动信息
GRUB_CMDLINE_LINUX=""
#属性名:手动添加内核启动参数
#值说明:默认为空,可以添加你需要的参数,以 “name=value” 的格式添加,多个参数用空格隔开
#例如:GRUB_CMDLINE_LINUX="name1=value1 name2=value2"
# Uncomment to enable BadRAM filtering, modify to suit your needs
# This works with Linux (no patch required) and with any kernel that obtains
# the memory map information from GRUB (GNU Mach, kernel of FreeBSD ...)
#GRUB_BADRAM="0x01234567,0xfefefefe,0x89abcdef,0xefefefef"
# Uncomment to disable graphical terminal (grub-pc only)
#GRUB_TERMINAL=console
#属性名:是否使用图形介面
#值说明:默认使用图像界面,去掉前面的“#”则使用控制台终端
# The resolution used on graphical terminal
# note that you can use only modes which your graphic card supports via VBE
# you can see them in real GRUB with the command `vbeinfo'
#GRUB_GFXMODE=640x480
#属性名:图形界面分辨率
#值说明:分辨率啦(还要怎么说明),修改时记得去掉前面的“#”
# Uncomment if you don't want GRUB to pass "root=UUID=xxx" parameter to Linux
#GRUB_DISABLE_LINUX_UUID=true
#属性名:grub命令是否使用UUID
#值说明:不知道是干什么的,不常用(如果你知道,欢迎留言,谢谢)
# Uncomment to disable generation of recovery mode menu entries
#GRUB_DISABLE_RECOVERY="true"
#属性名:是否创建修复模式菜单项
#值说明:true:禁用,false:使用,默认false
# Uncomment to get a beep at grub start
#GRUB_INIT_TUNE="480 440 1"
#属性名:启动时发出哔哔声
#值说明:默认不发声,去掉“#”则发声,值是什么意思不明白(应该是发出声音方式吧)
查看前10内存占用最多的进程
ps aux | sort -k4,4nr | head -n 10
查看进程的状态,VmRSS即为内存占用数值
cat /proc/2913/status
zip解压文件名乱码
unzip -O cp936 ziti.zip -d ziti_package
拷贝目录及其子目录下的文件
cp $(find /oldboy/ -type f -name "*.sh") /tmp
find -type f -name "*.sh" | xargs -i cp {} /tmp
find -type f -name "*.sh" -exec cp {} /tmp \;
find -type f -name "*.sh" | xargs cp -t /tmp
编译onlyoffice会用到的一些命令行
# 编译 x2t
cd /data/onlyoffice/DocumentServer/core/build/bin/linux_64
rm ./*
cd /data/onlyoffice/DocumentServer/build_tools/makefiles
make -f build.makefile_linux_64 -j 20
cd /data/onlyoffice/DocumentServer/core/build/bin/linux_64
cp x2t /data/onlyoffice/FileConverter/Bin/
cp -r ../../lib/linux_64/* /data/onlyoffice/FileConverter/Bin/
cd /data/onlyoffice/FileConverter
./Bin/x2t bin2docx.xml
#将canvas变成图片下载下来
url=page.drawingPage.cachedImage.image.toDataURL("image/png")
var oA = document.createElement("a");
oA.download = 'donwload';// 设置下载的文件名,默认是'下载'
oA.href = url;
document.body.appendChild(oA);
oA.click();
oA.remove(); // 下载之后把创建的元素删除
#下载PDSE图片
url=PDSE.Graphics.m_oContext.canvas.toDataURL("image/png")
var oA = document.createElement("a");
oA.download = 'donwload';// 设置下载的文件名,默认是'下载'
oA.href = url;
document.body.appendChild(oA);
oA.click();
oA.remove(); // 下载之后把创建的元素删除
# 生成前后端字体文件
rm /datatt/sdkjs/common/AllFonts.js
rm /datatt/server/FileConverter/bin/AllFonts.js
rm /datatt/sdkjs/common/Images/*
rm /datatt/server/FileConverter/bin/font_selection.bin
rm /datatt/fonts/*
cd /data/onlyoffice/toolx/x2t/
./allfontsgen --input="./ziti" --allfonts-web="/datatt/sdkjs/common/AllFonts.js" --allfonts="/datatt/server/FileConverter/bin/AllFonts.js" --images="/datatt/sdkjs/common/Images" --selection="/datatt/server/FileConverter/bin/font_selection.bin" --output-web='/datatt/fonts' --use-system="false"
cp /datatt/sdkjs/common/AllFonts.js ../../../sdkjs/common/
cp /datatt/sdkjs/common/AllFonts.js ../../sdkjs/common/
cp /datatt/server/FileConverter/bin/AllFonts.js ../../FileConverter/Bin/
cp /datatt/server/FileConverter/bin/font_selection.bin ../../FileConverter/Bin/
cp /datatt/sdkjs/common/Images/* ../../../sdkjs/common/Images/
cp /datatt/sdkjs/common/Images/* ../../sdkjs/common/Images/
rm ../../python/static/web-apps/fonts/*
rm ../../python_test/static/web-apps/fonts/*
cp /datatt/fonts/* ../../python/static/web-apps/fonts/
cp /datatt/fonts/* ../../python_test/static/web-apps/fonts/
cp /datatt/sdkjs/common/AllFonts.js ../../python/static/web-apps/sdkjs_bak/common/
cp /datatt/sdkjs/common/AllFonts.js ../../python_test/static/web-apps/sdkjs_bak/common/
cp /datatt/sdkjs/common/AllFonts.js ../../python/static/web-apps/sdkjs/common/
cp /datatt/sdkjs/common/AllFonts.js ../../python_test/static/web-apps/sdkjs/common/
cp /datatt/sdkjs/common/Images/* /data/onlyoffice/python/static/web-apps/sdkjs/common/Images
cp /datatt/sdkjs/common/Images/* /data/onlyoffice/python/static/web-apps/sdkjs_bak/common/Images
cp /datatt/sdkjs/common/Images/* /data/onlyoffice/python_test/static/web-apps/sdkjs/common/Images
cp /datatt/sdkjs/common/Images/* /data/onlyoffice/python_test/static/web-apps/sdkjs_bak/common/Images
# 前端生成字体
rm /datatt/sdkjs/common/AllFonts.js
rm /datatt/server/FileConverter/bin/AllFonts.js
rm /datatt/sdkjs/common/Images/*
rm /datatt/server/FileConverter/bin/font_selection.bin
rm /datatt/fonts/*
cd /data/onlyoffice/toolx/x2t/
./allfontsgen --input="./ziti" --allfonts-web="/datatt/sdkjs/common/AllFonts.js" --allfonts="/datatt/server/FileConverter/bin/AllFonts.js" --images="/datatt/sdkjs/common/Images" --selection="/datatt/server/FileConverter/bin/font_selection.bin" --output-web='/datatt/fonts' --use-system="false"
cp /datatt/sdkjs/common/AllFonts.js ../../../sdkjs/common/
cp /datatt/sdkjs/common/AllFonts.js ../../sdkjs/common/
cp /datatt/sdkjs/common/Images/* ../../../sdkjs/common/Images/
cp /datatt/sdkjs/common/Images/* ../../sdkjs/common/Images/
rm ../../python/static/web-apps/fonts/*
rm ../../python_test/static/web-apps/fonts/*
cp /datatt/fonts/* ../../python/static/web-apps/fonts/
cp /datatt/fonts/* ../../python_test/static/web-apps/fonts/
cp /datatt/sdkjs/common/AllFonts.js ../../python/static/web-apps/sdkjs_bak/common/
cp /datatt/sdkjs/common/AllFonts.js ../../python_test/static/web-apps/sdkjs_bak/common/
cp /datatt/sdkjs/common/AllFonts.js ../../python/static/web-apps/sdkjs/common/
cp /datatt/sdkjs/common/AllFonts.js ../../python_test/static/web-apps/sdkjs/common/
cp /datatt/sdkjs/common/Images/* /data/onlyoffice/python/static/web-apps/sdkjs/common/Images
cp /datatt/sdkjs/common/Images/* /data/onlyoffice/python/static/web-apps/sdkjs_bak/common/Images
cp /datatt/sdkjs/common/Images/* /data/onlyoffice/python_test/static/web-apps/sdkjs/common/Images
cp /datatt/sdkjs/common/Images/* /data/onlyoffice/python_test/static/web-apps/sdkjs_bak/common/Images
mongo 和 mysql 命令比较
左边是mongodb查询语句,右边是sql语句。对照着用,挺方便。
db.users.find() select * from users
db.users.find({"age" : 27}) select * from users where age = 27
db.users.find({"username" : "joe", "age" : 27}) select * from users where "username" = "joe" and age = 27
db.users.find({}, {"username" : 1, "email" : 1}) select username, email from users
db.users.find({}, {"username" : 1, "_id" : 0}) // no case // 即时加上了列筛选,_id也会返回;必须显式的阻止_id返回
db.users.find({"age" : {"$gte" : 18, "$lte" : 30}}) select * from users where age >=18 and age <= 30 // $lt(<) $lte(<=) $gt(>) $gte(>=)
db.users.find({"username" : {"$ne" : "joe"}}) select * from users where username <> "joe"
db.users.find({"ticket_no" : {"$in" : [725, 542, 390]}}) select * from users where ticket_no in (725, 542, 390)
db.users.find({"ticket_no" : {"$nin" : [725, 542, 390]}}) select * from users where ticket_no not in (725, 542, 390)
db.users.find({"$or" : [{"ticket_no" : 725}, {"winner" : true}]}) select * form users where ticket_no = 725 or winner = true
db.users.find({"id_num" : {"$mod" : [5, 1]}}) select * from users where (id_num mod 5) = 1
db.users.find({"$not": {"age" : 27}}) select * from users where not (age = 27)
db.users.find({"username" : {"$in" : [null], "$exists" : true}}) select * from users where username is null // 如果直接通过find({"username" : null})进行查询,那么连带"没有username"的纪录一并筛选出来
db.users.find({"name" : /joey?/i}) // 正则查询,value是符合PCRE的表达式
db.food.find({fruit : {$all : ["apple", "banana"]}}) // 对数组的查询, 字段fruit中,既包含"apple",又包含"banana"的纪录
db.food.find({"fruit.2" : "peach"}) // 对数组的查询, 字段fruit中,第3个(从0开始)元素是peach的纪录
db.food.find({"fruit" : {"$size" : 3}}) // 对数组的查询, 查询数组元素个数是3的记录,$size前面无法和其他的操作符复合使用
db.users.findOne(criteria, {"comments" : {"$slice" : 10}}) // 对数组的查询,只返回数组comments中的前十条,还可以{"$slice" : -10}, {"$slice" : [23, 10]}; 分别返回最后10条,和中间10条
db.people.find({"name.first" : "Joe", "name.last" : "Schmoe"}) // 嵌套查询
db.blog.find({"comments" : {"$elemMatch" : {"author" : "joe", "score" : {"$gte" : 5}}}}) // 嵌套查询,仅当嵌套的元素是数组时使用,
db.foo.find({"$where" : "this.x + this.y == 10"}) // 复杂的查询,$where当然是非常方便的,但效率低下。对于复杂查询,考虑的顺序应当是 正则 -> MapReduce -> $where
db.foo.find({"$where" : "function() { return this.x + this.y == 10; }"}) // $where可以支持javascript函数作为查询条件
db.foo.find().sort({"x" : 1}).limit(1).skip(10); // 返回第(10, 11]条,按"x"进行排序; 三个limit的顺序是任意的,应该尽量避免skip中使用large-number
查找文件
grep -r '查找内容' ./
-r 或者 -R 为递归查找, -n 是行号 -w 为要求全匹配. -l (小写L) 参数可以只列出文件名.
git回退版本
git reset --hard commit_id #切换到某个commit_id对应的版本
git push origin HEAD --force #将这个head推送到远程,不触发更新
git 放弃所有本地修改
git reset --hard
如果helper.cpp一直编译不成功,但是使用bash可以正常编译,但是使用远程的python却不能够编译成功,尝试装了python3-dev之类的依旧不能够编译成功,我们可以装ninja-build
apt-get install ninja-build
kibana dev tools 一些示例语法:
GET sov_index/_search
{
"query": {
"match_all": {}
}
}
GET sov_index/_count
POST sov_index/_delete_by_query
{
"query": {
"match_all": {}
}
}
POST sov_index/_search
{
"query": {
"match": {
"FIELD": {"subject":"LED"}
}
}
}
POST /sov_index/_search
{
"query": {
"bool": {
"must": [
{
"query_string": {
"default_field": "subject",
"query": "R2"
}
},
{
"query_string": {
"default_field": "verb",
"query": "完成"
}
}
]
}
}
}
DELETE sov_index
PUT sov_index
{
"settings": {
"number_of_shards": 9,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"subject":{
"type": "text",
"analyzer": "whitespace"
},
"object":{
"type": "text",
"analyzer": "whitespace"
},
"verb":{
"type": "text",
"analyzer": "whitespace"
},
"sentence":{
"type": "text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart"
}
}
}
}
POST /sov_index/_flush
重置gitlab密码: gitlab-rake "gitlab:password:reset[root]"